Loading... # Data Mining - Week1 > Slides: [Introduction.pptx](/usr/uploads/2021/09/3914639704.pptx) ## 1.1 Learning Resource 书籍: - *Introduction to Data Mining* - *Data Mining : Practical Machine Learning Tools and Techniques* - *Beautiful Data : The Stories Behind Elegant Data Solutions* - *数据挖掘概念与技术* - *模式分类* 会议: - International Conference on Data Mining - International Conference on Data Engineerning - International Conference on Machine Learning - International Joint Conference on Artificial Intelligencce - Pacific-Asia Conference on Knowledge Discovert and Data Mining - ACM SIGKDD Conference on Knowledge Discovery and Data Mining 数据集: - Uci Machine Learning Repository: http://archive.ics.uci.edu/ml/datasets.php ## 1.2 Interdisciplinary **数据挖掘** 是一个多交叉学科领域, 包含了**机器学习**, **人工智能**, **模式识别**, **统计学** 等等. **数据挖掘** 广泛应用于各个领域: - Business Intelligence - Data Analytics - Big Data - Decision Support - Customer Relationship Management ## 1.3 Data **DRIP**: Data Rich, Information Poor ### 1.3.1 Big Data #### 3V - **Volumn**: Terabytes $\to$ Zerrabytes - **Variety**: Structured $\to$ Structured & Unstructured - **Velocity**: Batch $\to$ Streaming Data #### Application - Public Security - Health Care Application - Urban Planning (Location Data) - Mobole User (Location Data) - Shopper (Location Data) - Targeted Marketing (Retail Data) - ... ### 1.3.2 Open Data - Technically Open: 将数据转化为机器可读的标准格式, 能够更好的被计算机应用程序处理 - Legally Open: 可以不受限制的方式进行商业或非商业用途 #### Some Data Repositories - Open Government Data: https://www.data.gov/ -  -  ## 1.4 Data Mining *Definition*: Data Mining is the process of automatically extracting **interesting** and **useful hidden** patterns from usually **massive**, incomplete and noisy data ### 1.4.1 From Data To Intelligence 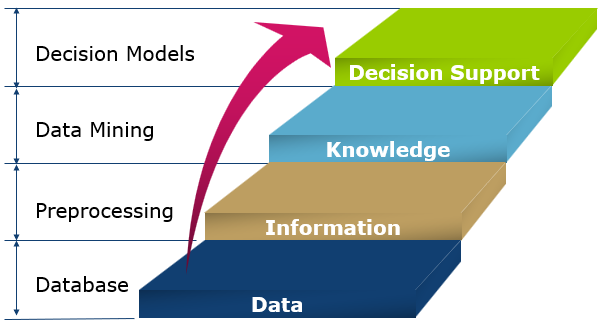 ### 1.4.2 Data Integration & Analysis  数据通常分布在各个地方, 如OS, ERP, CRM或文件等, 需要通过ETL将各个数据进行提取、转换、装载后, 存放在数据仓库之中, 才能进行Data Mining, Data Analysis 等工作. > ETL: Extraction(提取), Transformation(转换), Loading(装载) ## 1.5 Techniques ### 1.5.1 Classification > Ref: https://mki.moe/ml2021spring/ML-2021-Spring-Chap2.html#Classification <div class="preview"> <div class="post-inser post box-shadow-wrap-normal"> <a href="https://mik.moe/ml2021spring/ML-2021-Spring-Chap2.html" target="_blank" class="post_inser_a no-external-link no-underline-link"> <div class="inner-image bg" style="background-image: url(https://mik.moe/usr/themes/handsome/assets/img/sj/1.jpg);background-size: cover;"></div> <div class="inner-content" > <p class="inser-title">Chapter 2 机器学习攻略</p> <div class="inster-summary text-muted"> Chapter.2 机器学习攻略PDF: https://mki.moe/usr/uploads/2021/07/... </div> </div> </a> <!-- .inner-content #####--> </div> <!-- .post-inser ####--> </div> *Definition*: Classification is a procedure in which individual items are placed into groups based on quantitative information on one or more characteristics (referred to as variables) and based on a training set of previously labeled items. *Process*: Given a training set $D=\{(x_1,y_1),\ldots, (x_n, y_n)\}$, produce a classifier (function) that maps any unknown object $x_i$ to its class label $y_i$. *Algorithms*: - Decision Tree - K-Nearest Neighbours - Neural Networks - Support Vector Machines *Applications*: - Churn Prediction - Medical Diagnosis 实质: 对空间进行划分 #### Confusion Matrix > Ref: https://mki.moe/weekly/2021-06-28.html <div class="preview"> <div class="post-inser post box-shadow-wrap-normal"> <a href="https://mik.moe/weekly/2021-06-28.html" target="_blank" class="post_inser_a no-external-link no-underline-link"> <div class="inner-image bg" style="background-image: url(https://mik.moe/usr/themes/handsome/assets/img/sj/1.jpg);background-size: cover;"></div> <div class="inner-content" > <p class="inser-title">2021.6.28 周记</p> <div class="inster-summary text-muted"> 2021.6.28 周记上一周的学习内容1. 机器学习的性能度量性能度量 (performance measure... </div> </div> </a> <!-- .inner-content #####--> </div> <!-- .post-inser ####--> </div> 对于二分类问题可以将样例根据类别划分为 `真正例 (true positive)`, `假正例 (false positive)` , `真反例 (true negative)`, `假反例 (false negative)` | 真实情况 \ 预测结果 | 正例 | 反例 | | :---: | :----: | :----: | | 正例 | $TP$ | $FN$ | | 反例 | $FP$ | $TN$ | #### Receiver Operating Characteristic (ROC) 根据学习器的预测结果对样例进行排序, 按此顺序逐个把样本作为正例进行预测, 每次计算出假正例率和真正例率, 以 `真正例率 (True Positive Rate)` 为纵轴, `假正例率 (False Positive Rate)` 为横轴绘制的图为 `ROC` #### Area Under ROC Curve (AUC) ROC曲线下的面积为AUC $$ AUC = \frac{1}{2}\sum^{m-1}_{i=1}(x_{i+1}-x_i)\cdot(y_i+y_{i+1}) $$ ### 1.5.2 Clustering > Ref: https://mki.moe/weekly/2021-08-16.html <div class="preview"> <div class="post-inser post box-shadow-wrap-normal"> <a href="https://mik.moe/weekly/2021-08-16.html" target="_blank" class="post_inser_a no-external-link no-underline-link"> <div class="inner-image bg" style="background-image: url(https://mik.moe/usr/themes/handsome/assets/img/sj/1.jpg);background-size: cover;"></div> <div class="inner-content" > <p class="inser-title">2021.8.16 周记</p> <div class="inster-summary text-muted"> 2021.8.16 周记上一周的学习内容1. Self-supervised LearningSupervised... </div> </div> </a> <!-- .inner-content #####--> </div> <!-- .post-inser ####--> </div> *Definition*: Clustering is the assignment of a set of observations into subsets (called clusters) so that observations in the same cluster are similar in some sense. *Distance Metrics*: - Euclidean Distance - Manhattan Distance - Mahalanobis Distance *Algorithms*: - K-Means - Sequential Leader - Affinity Propagation *Applications*: - Market Research - Image Segmentation - Social Network Analysis ### 1.5.3 Association Rule 根据数据关联得到信息. 如: 通过牛奶和面包得出用户需要购买黄油 ### 1.5.4 Regression 通过学习一个线性模型使其尽可能准确地预测新样本的输出值 ## 1.6 Data Preprocessing **G.I.G.O**: Garbage In, Garbage Out. 如果输入的是垃圾数据, 那么输出也不会有效. 如果数据读入通常是脏数据, 我们通常需要数据预处理对脏数据进行清洗等工作. ## 1.7 Some Issue - **Privacy Protection** - **Clout Computing**: 弹性扩容避免机器资源浪费 (Pay As You Go) - **Parallel Computing**: GPU 作为计算卡, 科学计算, 廉价的超级计算 最后修改:2021 年 10 月 09 日 © 允许规范转载 赞 0 如果觉得我的文章对你有用,请随意赞赏