Loading... ## 主要内容 1. 关于强化学习 2. 关于POMDP强化学习,如何实现智能决策 3. 如何将RL智能决策与验证系统相结合 ## 1. 关于强化学习(Reinforcement Learning) 强化学习时机器学习的一个领域,在强化学习中,现实世界被分为智能体和环境,智能体基于环境而行动,智能体目标通过接受环境互动的反馈做出相应的动作,以取得最大化的预期利益. [^1] 尽管强化学习与监督学习都是使用输入输出映射的模型,但不同于监督学习反馈给智能体的是正确的行动集合,强化学习使用带有积极或消极意义的奖励函数反馈给智能体(即奖励和惩罚)[^2] 强化学习研究的主要问题是智能体(agent)和环境(environment)相互交互的问题: 智能体将自身行为动作(action)传输给环境, 环境根据动作转换到一个新的状态(state), 并计算当前状态环境给出奖励信号(reward),将状态和信号传输给智能体,智能体通过得到的状态和信号,通过一定的策略(policy)得到下一步的动作.[^3] 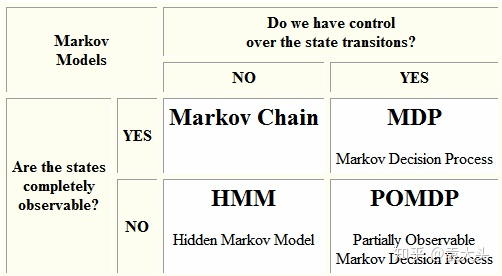 [^1]: Ding Z, Huang Y, Yuan H, et al. Introduction to reinforcement learning[J]. Deep Reinforcement Learning: Fundamentals, Research and Applications, 2020: 47-123. [^2]: A review On reinforcement learning: Introduction and applications in industrial process control [^3]: Thrun S, Littman M L. Reinforcement learning: an introduction[J]. AI Magazine, 2000, 21(1): 103-103. ## 2. 关于POMDP强化学习的内容,如何实现智能决策 强化学习所研究的是作为主体的智能体与作为客体的环境交互的序贯决策过程. 根据智能体能否完全观测环境状态的情况可分为MDP和POMDP. 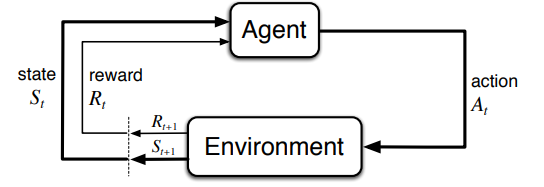 ### 2.1 什么是MDP 马尔可夫决策过程(Markov decision process,MDP)是马尔科夫链的延申,强化学习中,状态是对世界的完整描述,智能体和环境都会根据历史的所有数据和行为(action, reward, observed)的集合 $H_t^{a,e}$ 进行状态更新,若智能体能够完全观测环境状态(两者状态等价),则问题可被定义为MDP问题. [^4] > Zhihu: https://zhuanlan.zhihu.com/p/159621634 > 个人理解: 智能体如果能够与环境同等获取整个世界的信息(完全观测, fully observed),此时可以被定义为MDP. MDP可以理解为从state到action的映射 MDP的目标是寻找一个好的策略(Policy)$\pi$去最大化奖励函数, 最终得到最优解 $\pi^\ast$ [^4]: Xiong W, Zhong H, Shi C, et al. Nearly minimax optimal offline reinforcement learning with linear function approximation: Single-agent mdp and markov game[J]. arXiv preprint arXiv:2205.15512, 2022. ### 2.2 POMDP > wiki: https://en.wikipedia.org/wiki/Partially_observable_Markov_decision_process > zhihu: https://www.zhihu.com/question/20683006 在一些实际环境中,环境的状态机和并不能完全被智能体所观测到,此时,智能体无法知道自己所处的环境状态,只能通过其余智能体或传感器得到自身状态,此时环境仅可被部分观测(partially observed), 此时无法使用MDP定义问题而建模成部分可观测马尔可夫决策过程(partially observable Markov decision process, POMDP)[^5] 相比较于MDP, POMDP更加的普遍。相应的,如果问题能够被完整定义为MDP,则通常较容易求解得到一个最优决策; <mark>而POMDP相较于MDP则存在一定的困难, 通常需要引入信念状态(Belief State)进行求解.</mark> [^5]: Bhattacharya S, Badyal S, Wheeler T, et al. Reinforcement learning for POMDP: Partitioned rollout and policy iteration with application to autonomous sequential repair problems[J]. IEEE Robotics and Automation Letters, 2020, 5(3): 3967-3974. ## 3. 如何将RL智能决策与验证系统相结合 强化学习通过在众多策略中进行探索从而得到最优策略。安全强化学习(Safe reinforcement learning, SRL)指在满足安全约束的情况下, 通过最大化期望回报值得到最优策略.[^6] 在普通训练策略上,有两种方向修改策略以训练更加安全强化学习模型: - 修改优化标准,引入风险概念 <mark>(可以理解为在监督学习中修改损失函数, 添加风险相关计算)</mark> - 修改探索过程,以避免可能导致学习系统陷入不理想或灾难性情况的探索行动 <mark>(可以理解为搜索树剪枝)</mark> 论文[^7] 3.2节里面, shield的引入保证智能体的动作限定在安全的范围内(文章中称winning region), 即对应上面修改策略的第二条. 同时, 论文[^7]对于模型安全提出了要求: - Safety during learning; - Safety after learning. [^6]: Garcıa J, Fernández F. A comprehensive survey on safe reinforcement learning[J]. Journal of Machine Learning Research, 2015, 16(1): 1437-1480. [^7]: Carr S, Jansen N, Junges S, et al. Safe Reinforcement Learning via Shielding under Partial Observability[J]. arXiv preprint arXiv:2204.00755, 2022. 最后修改:2023 年 04 月 09 日 © 允许规范转载 赞 0 如果觉得我的文章对你有用,请随意赞赏