Loading... # 2021.8.16 周记 ## 上一周的学习内容 ### 1. Self-supervised Learning - Supervised 将样本作为输入 $x$ 通过模型进行训练, 得到训练结果 $y$, 将其余标签 $\hat{y}$ 进行比对. - Self-Supervised 将样本 $x$ 分为 $x'$ 和 $x''$, 先将 $x'$ 通过模型进行训练, 得到训练结果 $y$, 再将 $y$ 与 $x''$ 进行比对. #### BERT > BERT = Encoder of Transformer 从大量的文本中学习, 做的事情时是每句话输出一个 vector. ##### BERT训练过程 > 以下两种训练方法是同时使用 ###### 1. Masked LM 有15%的几率盖住输入, 让BERT通过预测将其填回来 ###### 2. Next Sentence Prediction 用一个特殊的 token 告诉要做 Classifier 这件事情 > - [CLS]: the position that outputs classification results > - [SEP]: the boundary of two sentences ##### BERT使用 ###### Case 1 - 输入: 句子 - 输出: 类别 - 例子: 情感分析, 文件分类  ###### Case 2 - 输入: 单句 - 输出: 每个词的类别 - 例子: POS tagging 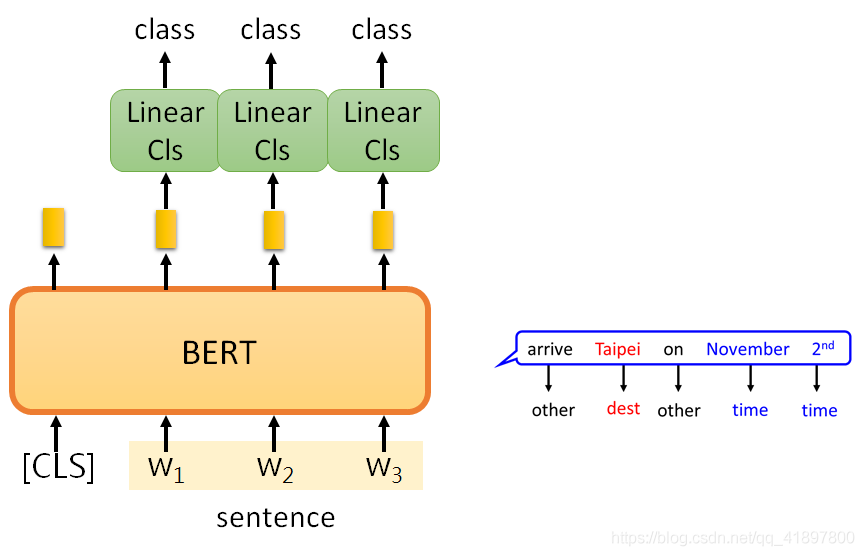 ###### Case 3 - 输入: 两句 - 输出: 类别 - 例子: 自然语言处理 (Natural Language Inferencee, NLI)  ###### Case 4 基于提取的问题回答 - Document: $D = \{d_1, d_2, \cdots, d_N\}$ - Query: $Q = \{q_1, q_2, \cdots, q_M\}$ - Answer: $A = \{d_s, \cdots, d_e\}$ 输入 $D$, $Q$. 输出 $s$, $e$ (integer). 表示第 $s \dots e$ 个词汇为答案. 聚类 ##### BERT扩展工作 BERT训练过程需要耗费非常多的资源, 所以大家致力于研究`BERT胚胎学`, 研究训练中模型的发展过程. - `Pre-train seq2seq模型`: 将一些故意错误的输入给Encoder, 要求 Decoder 输出原本完好的数据. - `multi-bert`: 可以进行zero-shot阅读理解 - ... #### GPT 预测下一个token, 类似于 Transformer 的 Decoder. 所以GPT有生成能力. - Few-shot learning - one-shot learning - zero-shot learning --- ### 2. 自编码器(Autoencoder) > Autoencoder 可以视为 Self-supervised 中 Pre-train 的一种, 因为同样没有应用到标签数据 Autoencoder 流程和 CycleGAN 类似, 常见作用是降维. 可以用来做压缩, 解压, lossy compression. --- ### 3. 聚类 #### 聚类任务 - 无监督学习 (unsupervised learning) - **定义**: 训练样本的标记信息是未知的, 目的是通过对无标记训练样本的学习来揭示数据的内在性质及规律, 为进一步的数据分析提供基础 - 通常用于密度估计, 异常检测 - 聚类 (clustering) - 将数据集中的样本划分为若干个通常是不想交的子集. - 子集称之为 `簇 (cluster)` 聚类问题一般研究两个基本问题: - 性能度量 - 距离计算 #### 性能度量 > 性能度量也称聚类 `有效性指标 (validity index)` - 主要用途 1. 对聚类的结果的好坏进行评估 2. 作为聚类过程的优化目标 - 衡量方式 - `簇内相似度 (intra-cluster similarity)` 高 - `簇间相似度 (inter-cluster similarity)` 低 - 度量方式 - 度量方式通常分为: 外部指标 (external index), 内部指标(internal index) - 外部指标: 将聚类结果于某个参考模型进行比较, 常见计算方式有: Jaccard 系数, FM 指数, Rand 指数. - 内部指标: 直接考察聚类结果而不利用任何参考模型, 常见计算方式有: DB 指数, Dunn 指数. #### 距离度量 ##### 距离函数 $$ \text{dist}(\cdot, \cdot) $$ 其定义是一个距离度量. **基本性质**: - 非负性: $\text{dist}(\boldsymbol{x}_i,\boldsymbol{x}_j) \ge 0$ - 同一性: $\text{dist}(\boldsymbol{x}_i,\boldsymbol{x}_j) = 0$, 仅当 $\boldsymbol{x}_i = \boldsymbol{x}_j$ - 对称性: $\text{dist}(\boldsymbol{x}_i,\boldsymbol{x}_j) = \text{dist}(\boldsymbol{x}_j, \boldsymbol{x}_i)$ - 直递性: $\text{dist}(\boldsymbol{x}_i,\boldsymbol{x}_j) \le \text{dist}(\boldsymbol{x}_i,\boldsymbol{x}_k) + \text{dist}(\boldsymbol{x}_k,\boldsymbol{x}_j)$ > 这些性质可以检测函数是否可以作为距离度量函数 #### 原型聚类 > `原型 (prototype)` 是指样本空间中具有代表性的点 **原型聚类的三种学习算法**: - k-均值算法 (k-means) - 学习向量化 (LVQ) - 高斯混合聚类 (GMM) #### 密度聚类 > 又称 `基于密度的聚类 (density-based clustering)`, 这类算法假设聚类结构能通过样本分布的紧密程度确定. **密度聚类算法**: - DBSCAN (Density-Based Spatial Clustering of Applications with Noise) #### 层次聚类 > 层次聚类 (hierarchical clustering) 试图在不同层次对数据集进行划分, 从而形成树形的聚类结构. **层次聚类算法**: - AGNES --- ### 4. Torch 实现一些模型 代码: https://github.com/beiyanpiki/mlbook/blob/main/notebooks/004%20softmax%E5%9B%9E%E5%BD%92.ipynb ## 本周学习计划 1. 周志华 《机器学习》 Ch.10 降维与度量学习 2. 李宏毅2021春机器学习课程 Adversarial Attack, Explainable ML 3. 看论文 4. 尝试自己实现一些模型的代码 最后修改:2021 年 08 月 19 日 © 允许规范转载 赞 0 如果觉得我的文章对你有用,请随意赞赏